SharePoint to Oracle data conversion
The purpose of this post is to document the process I used to convert the data from a Microsoft SharePoint site to an Oracle database with an APEX front end. However, there won’t be much about APEX in this post, sorry. This one is all about the data conversion.
Sure, SharePoint does allow you to easily export its data to flat file or Excel, however this approach doesn’t scale too well when you need to repeat and test your conversion scripts several times. I was dealing with 20 source lists (think tables) that needed to be extracted, transformed and mapped into their final Oracle tables. It was clear that we needed repeatability in the conversion process and thus connecting directly to the Microsoft SQL Server schema and moving the data over to Oracle was a better approach.
At a high level, the approach had these steps:
- Use Oracle SQL Developer to copy the (“as-is”) data from SQL Server to Oracle.
- Create all the objects in the Oracle database schema.
- Run the scripts that will massage, transform and move the data.
- Rinse and repeat (Until testing and validations were successful).
Using Oracle SQL Developer
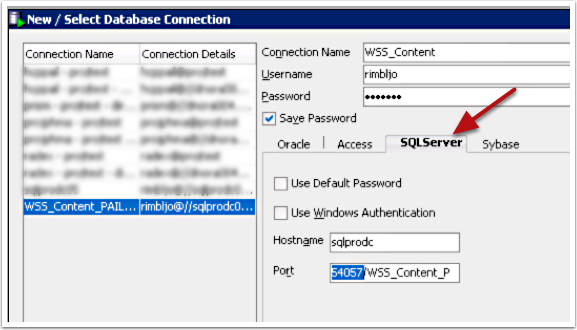
Without SQL Developer this whole process would have been unnecessarily complicated. SQL Developer has the very nifty ability to connect to other non-Oracle databases and data sources via it’s support of Third Party JDBC Drivers. When the necessary JDBC Driver is present, SQL Developer will present the corresponding tab on the connection dialog. Jeff Smith explains the feature best in his Connecting to Access, DB2, MySQL, SQL Server, Sybase, & Teradata with SQL Developer blog post. We connected directly to the SQL Server database using the jTDS SQL Server JDBC driver that we found thanks to this other post.
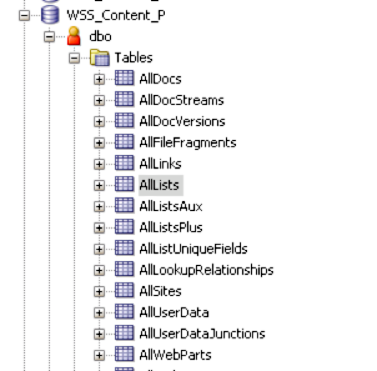
Now, I’ll warn you, at the client site no one had ever connected to this SQL Server database without a fancy-autodiscovery-autoconfigured GUI tool. It took many back and forth emails and support calls to determine the correct connection settings we needed. Now, I’m by no means a SQL Server expert, so I could be using the incorrect terminology here, but here’s what worked for me. We did use the name of the machine for the host name. The key as you can see from the connect image was in the port field. We used port slash site. I don’t really know if that word after the port is the site, schema, instance or what. Like I said, it took several tries and combinations. However, once the connection worked everything went pretty smooth. This is what we were able to see in the SQL Developer Connections Panel.
The SharePoint Data
The SharePoint data we needed was stored in only 5 tables:
- AllLists
- AllUserData
- AllUserDataJunctions
- AllDocs
- AllDocStreams
User data in SharePoint is usually stored in lists. Everything is a list and AllLists has the name and IDs for those lists, think the “Header” record. AllUserData is the bulk of all the data. All the list data is stored here, think “Lines” that join to a header. AllUserData has many columns with generic names like nvarchar1, nvarchar2, nvarchar3, int1, int2, bit1, bit2, ntext1, ntext2, etc.. you get the idea. The AllUserDataJunctions is basically a lookups and joins table. It contains the relationship between two lists. The AllDocs and AllDocStreams worked together to store the documents we needed. AllDocs contained the document information, the header if you will and AllDocStreams contained the BLOB with the document. Other than sorting out the relationship between the AllLists, AllUserData, AllDocs and AllDocStreams I was pleasantly surprised that we were able to extract the binaries (BLOBs) documents we needed.
Moving the Data
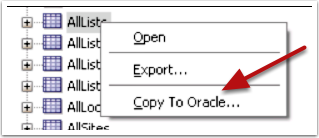
Next, from the Connections panel, in SQLDev, we right click on the object we want to copy to our Oracle database and select “Copy to Oracle…”. A dialog will pop-up where we need to select the destination connection we want to copy the data to. The connection must already exist. You’ll see a checkbox to “Include Data” and a radio button group labeled “Options if the table exists” with the following three options: Indicate Error, Append, or Replace.
I would mostly use the “Append” option because I was controlling cleaning the tables, but it’s your choice.
Now, the first time it runs, this step will create the table and fail with this error:
Table AllLists Failed. Message: ORA-01400: cannot insert NULL into ("MYSCHEMA"."ALLLISTS"."TP_DELETETRANSACTIONID")
But it doesn’t completely fail, it does create the table. We just need to make the TP_DELETETRANSACTION_ID column nullable:
alter table AllUserData modify TP_DELETETRANSACTIONID RAW(32) null;
Notice that the datatype is RAW(32), maybe this is why SQLDev maps the column incorrectly, who knows. But after fixing this we can try the copy again. The AllList table is fairly small and we quickly see:

Then we move to AllUserData. It also fails on the TP_DELETETRANSACTIONID column so we fix it with:
alter table AllUserData modify TP_DELETETRANSACTIONID RAW(32) null;
Repeat the “Copy to Oracle”. While this is running we see this dialog:
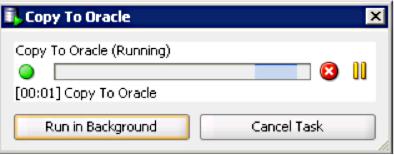
In my case, it took around 10 minutes to complete.
We also need AllUserDataJunctions. We repeat the “Copy To Oracle”. It will also fail. We fix the table and try again.
We repeat for AllDocs. Except, in this case, the column to fix is DELETETRANSACTIONID. So we run this command:
alter table AllDocs modify DELETETRANSACTIONID RAW(32) null;
Next we can copy AllDocStreams. There is no column to fix here. This is the table that contains the actual document BLOB column and all the versions of the documents. It may take a while to run.
Finally, I created some indexes to speed things up before running the conversion scripts.
create index AllUserData_i01 on AllUserData(tp_ListId);
create index AllUserData_i02 on AllUserData(tp_Id);
create index alluserdatajunctions_i01 on alluserdatajunctions(tp_fieldid);
We’re done! All the data is now in Oracle and ready for conversion.
I’m not saying the process is completely automated, far from it, but it’s a lot faster, repeatable and reliable than extracting 20 different lists and then loading them into the database.
The Data Mapping
At this point, since all the data we need is now in our familiar Oracle tables, this becomes a data mapping/massaging exercise. If you look at the AllLists table, it will be clear what lists you have available and it should be trivial to map them to what you see on the SharePoint Site. The TP_TITLE column has the name of the list.
Mapping the columns on AllUserData is a little more involved. However, depending on your data, this is not necessarily complicated, it’s just busy work. I created views for all the lists I needed in order to make it a lot easier to work with. Here’s a view for the Country lists which basically contained the country_id, country name and country_code.
create or replace view wss_country
as
select d.tp_id country_id
, d.nvarchar1 country
, d.nvarchar3 country_code
, d.tp_author created_by
, d.tp_created create_date
, d.tp_editor updated_by
, d.tp_modified update_date
from alllists l
, alluserdata d
where d.tp_listid = l.tp_id
and l.tp_title = 'Country'
and d.tp_iscurrent = 1;
It was simply a matter of looking at the SharePoint list and the data in AllUserData to find and map nvarchar1 and nvarchar3. The same exercise was repeated for 19 other lists.
While mapping the more complex lists I learned some useful things:
- The floatN (float1, float2, etc) and intN columns contain numeric values and floats don’t necessarily have decimals, it would depend on your data.
- The ntextN fields contain multi-line data, but of course they fit perfectly into a varchar2.
- The bitN (bit1, bit2, etc..) columns are used for checkboxes in SharePoint and they simply had a 1 when set or a zero or null when not.
Dealing with AllUserDataJunctions
This table was a little more involved. Here’s the example of Suffixes assigned to “people”. First we needed a view on the possible Suffixes. This is easy, it’s the same scenario as above for countries.
create or replace view wss_suffixes
as
select d.tp_id suffix_id
, d.nvarchar1 suffix
from alllists l
, alluserdata d
where d.tp_listid = l.tp_id
and l.tp_title = 'Suffix'
and d.tp_iscurrent = 1;
Then we need to figure out the suffixes assigned to people. Using a previously created wss_people view, here’s the view that would combine return all the suffixes assigned to people.
create or replace force view wss_people_suffixes_xref
as
select p.people_id
, d.tp_id suffix_id
, d.nvarchar1 suffix
, d.tp_author
, d.tp_created
, d.tp_editor
, d.tp_modified
from alluserdata d,
(select a.tp_id
, wssp.people_id
from alluserdatajunctions a
, wss_people wssp
where a.tp_fieldid = '50F1CA52-3D21-45A1-A23D-C6A556A74144'
and a.tp_isCurrentversion = 1
and a.tp_docid = wssp.tp_docid) p
where tp_listid = 'F5A9D1ED-9136-4604-8C52-A7448CD08A42'
and d.tp_iscurrent = 1
and d.tp_id = p.tp_id;
The tp_fieldid required a little of poking around and searching for unique enough values to find it. The tp_listid is just a list id. We were able to use the exact same construct for a few other cross references that used the AllUserDataJunctions table.
Dealing with AllDocs and AllDocStreams
When I think about SharePoint, I usually imagine a document repository. However, that was not the case for this site. This was growing to something a lot more complex (hence the need for the conversion). As such, documents in this system were all assigned to the people entity. It did not have a generic document repository (another reason it was a good candidate for conversion). I would imagine that if you were extracting a regular document repository the documents would be part of a special “Documents” list. However, at this time I’m unable to confirm this.
Here’s the view we used to extract documents.
create or replace view wss_documents
as
select d.tp_id document_id
, d.tp_listid
, d.nvarchar3 extension
, d.nvarchar7 title
, d.nvarchar13 people_id
, d.nvarchar13 person_name
, d.int1 folder_id
, d.tp_author created_by
, d.tp_created create_date
, d.tp_editor updated_by
, d.tp_modified update_date
from alllists l
, alluserdata d
where d.tp_listid = l.tp_id
and l.tp_title = 'Document'
and d.tp_iscurrent = 1;
Notice nvarchar13 containing the people_id that links a particular document to a person. Then, here is the code to move the documents and the BLOB.
insert into myapp_documents
( id
, people_id
, folder_id
, title
, filename
, mime_type
, blob_content
, created_by
, created_on
, updated_by
, updated_on
)
select wd.document_id
, wd.people_id
, nvl(wd.folder_id, 1) folder_id
, wd.title
, d.leafname filename
, decode(lower(d.extension),
, 'pdf','application/pdf'
, 'doc','application/msword'
, 'pdf','application/pdf'
, 'aspx','application/x-asap'
, 'css','text/css'
, 'docx','application/msword'
, 'dotx','application/msword'
, 'gif','image/gif'
, 'htm','text/html'
, 'jpg','image/jpeg'
, 'png','image/png'
, 'ppt','application/vnd.ms-powerpoint'
, 'rtf','application/msword'
, 'vsd','application/visio'
, 'xls','application/vnd.ms-excel'
, 'xlsx','application/vnd.ms-excel'
, 'xml','text/xml'
, 'application/octet-stream'
) mime_type
, s.content
, wss_get_username(wd.created_by)
, wd.create_date
, wss_get_username(wd.updated_by)
, wd.update_date
from alldocstreams s
, alldocs d
, wss_documents wd
where d.doclibrowid = wd.document_id
and d.listid = wd.tp_listid
and d.internalversion = s.internalversion
and d.id = s.id
Notice two important things:
- The document binary/BLOB is in AllDocStreams.content
- We had to derive the MIME types from the document extension.
- wss_get_username is a simple function that maps IDs in SP to the users in the new system.
Disclaimer and Final Words
Everything you see here was done with SQL Developer v3.x, I have no reason to believe it would be any different with SQL Developer 4.x. I’m sorry to admit I have no clue which flavor or version of SharePoint I was accessing. My best guess is that this was the 2010 version. I also know that SharePoint has a lot of other features that fortunately we didn’t have to worry about. For example, we didn’t have to deal with Web-parts, social networking or wiki-pages.
If you’re facing a similar situation, I hope this helps you and gets you going in the right direction. I would love to hear about corrections or additions you may have to the information here or even better, tell me if this helped you out.








Hi, I'm Jorge Rimblas. Father, husband, photographer, Oraclenerd, Oracle APEX expert, Oracle ACE, coffee lover, car guy, gadget addict, etc... I'm an APEX Tech Lead DRW. I have worked with Oracle since 1995 and done eBusiness Suite implementations and customizations. Nowadays I specialize almost exclusively in Oracle APEX.
Great work, Thanks!
Very helpful!
Very nice article Jorge, this is definitely a nice solution if you need to migrate the data from Sharepoint to Oracle.
I needed a more integrated solution and went a different approach with using the webservices of Sharepoint. I will actually do a presentation at OOW14 about the integration of APEX and Sharepoint – in both directions (APEX content in Sharepoint and Sharepoint content in APEX). I’ll reference this post too!
Very cool! Yes, I think there’s always room to do both things in some environments: integrate and convert. The project where I did this conversion did include integration with other SharePoint sites that were not going away. That portion did turn into an integration with Oracle. However, I think the approach may have been more complicated than it needed to be. I won’t be at OOW14, but I’m looking forward to learning about it after you present. Thanks!